Resurgence in Neural Networks
If you’ve been paying attention, you’ll notice there has been a lot of news recently about neural networks and the brain. A few years ago the idea of virtual brains seemed so far from reality, especially for me, but in the past few years there has been a breakthrough that has turned neural networks from nifty little toys to actual useful things that keep getting better at doing tasks computers are traditionally very bad at. In this post I’ll cover some background on Neural networks and my experience with them. Then go over the recent discoveries I’ve learned about. At the end of the post I’ll share a sweet little github project I wrote that implements this new neural network approach.
Background
When I was in college I studied Cognitive Science, which is a interdisciplinary study of the mind and brain.
- Philosophy
- Psychology
- Linguistics
- Neuroscience
- Artificial Intelligence
I ended up focusing on A.I. and eventually majored in Computer Science because of it.
The prospect of using computers to simulate how our brains work was just fascinating to me.
And the possibility of applying those techniques would be nothing short of revolutionary. Now, when I say Artificial Intelligence I’m really only referring to Neural Networks. There are many other kinds of A.I. out there (e.g. Expert Systems, Classifiers and the like) but none of those store information like our brain does (between connections across billions of neurons).
The problem with using computers to simulate a brain is they work nothing like them. Computers have Central Processing Units. Brains are fully distributed. You teach computers what to-do by literally coding every action and response. Neural networks however, is a more generalized approach to computing. You teach computers how to learn… or at least that is the goal.
So how can you make a computer more like a brain? Well, a classic feed forward neural network is depicted below. In a neural network you have very simple primitives, nodes and weighted connections. Nodes connected to each other and the strength of that connection is how information is passed between them. By combining many nodes and connections together you can relay a variety of information that is quite stable and can cope with failures and unknown inputs. A common academic application for this kind of neural net is recognizing handwritten digits.
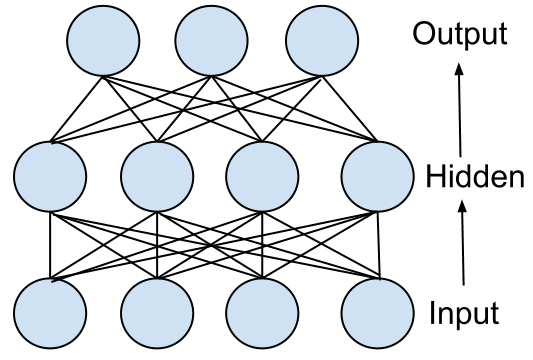
The input layer is where your input signal goes. For example, pixel intensities of a picture where each pixel maps to an input node. Each input node is connected to a node in the middle layer and each of those middle layer nodes are connected to the output layer. In the case of the handwriting example, each output node would map to a digit 0-9. Data feeds through the network in only one direction (hence the name feed forward). Now, the way our brain and a neural network stores information isn’t in the nodes themselves but actually in the connections between nodes. By using a training algorithm you can teach the network to adjust its weights so it will naturally extract features from the underlying data in the middle layer. As an example a ‘7’ digit has a sharp corner on the upper right.
The training algorithm taught to me in college years ago was called Backpropagation. It is tedious and not very accurate but it was state of the art A.I. It works like this:
You initialize the weights between nodes with some Gaussian noise. You process a sample input through the network and look at the activation of the output nodes. Based on the difference between the networks output and the desired output you adjust the contributing weights in the previous layers connections to dampen the wrong output and promote the right output. Then you move to the middle layer and adjust the connection weights from the input layer to the middle layer based on their contributions to the final output. This is a non-linear process so it is slow and requires A LOT of training cases. You can easily end up with weights stuck in local minima.
My first job out of college was building a neural network based model using backpropagation training to predict the yield of fiber optic lasers that met particular specs. The trouble was a linear regression model did a better job predicting the yield then my fancy neural network. This also happened to a lot of people who tried to use neural networks in the real world. Neural networks were replaced by things like PCA and Bayesian classifiers. These proved to be powerful tools that have created a whole new industry but they have little todo with how the brain works.
Over time I began to forget about neural networks and ended up getting interested in distributed databases. I was reminded, however, of how the brain works after having kids. To see them grow and learn you really appreciate how little we come into this world with. Everything from using their hands to grasp objects to recognizing your face is learned mainly unsupervised over months and months. A billion little neurons all working together to build a model of the world around them and how to interact with it.
A Breakthrough: Deep Learning with Restricted Boltzmann Machines
A few months ago I took a online course with coursera on neural networks and learned that while I had given up and moved on from neural networks, the original pioneers of neural nets hadn’t. And in 2002 Geoffrey Hinton (et al.) discovered a technique called called Contrastive Divergence that could quickly model inputs in a Restricted Boltzmann Machine. A Restricted Boltzmann Machine (RBM for short) is a two layer network of interconnected nodes (a bipartite graph). Unlike the feed forward network above these connections are two way. This is important because rather than using backpropagation and explicit output cases you try to model the input by bouncing it through the network. See below:

You pass the inputs up through the weights to the second layer then back down again, the goal being to re-generate the input. Then compare how close the input and the re-created input are and adjust the weights accordingly to improve the hidden layers representation of the input. Unlike backpropagation, this process is not very computationally complex. So you can quickly train this two layer network to do a good job of re-creating the input of a class of things.
Remember the example of hand written digits? The screenshot below shows what a RBM trained on digits looks like. The ‘3’ in the upper left is the never seen before test input and the 3’s below it are the RBM recreations for nine up/down cycles. The boxes to the right are renderings of the connections in the RBM. Each one represents all the input weights to a single hidden node. The green represents positive weights, the red represents negative weights. You can see the weights have changed to extract features from the class on inputs. Some are specifically focused on a single digit class while others are an amalgamation of different digit features.

Now you might be asking yourself what’s the value here if this network is only good at re-creating inputs? Well, first it can recognize new inputs of the same class it’s never seen before and redraw them using the features it’s discovered from training (as above). Even better it can not-recognize inputs that in no way represent the data it was trained on. For example if I show it a face when it was trained on digits you can easily look at the error and tell it’s not a digit.
More interestingly, Hinton discovered that you could stack these Restricted Boltzmann Machines one on top of the other and create what’s called a Deep Belief Network(DBN for short). By taking the output of one RBM and use it as the input of another RBM you can learn features of features and integrate different types of inputs together. This models a theory of how the brain works.
The neocortex of the brain [is] a hierarchy of filters where each layer captures some of the information in the operating environment, and then passes the remainder, as well as modified base signal, to other layers further up the hierarchy. The result of this process is a self-organizing stack of transducers, well-tuned to their operating environment. 1
In Hinton’s online class, his example is of a deep network builds on the handwriting example and connects four RBMs together. The first RBM is as described above. The second RBM takes the output from the first and uses it as it’s input. The third RBM takes the output from the second and uses it as it’s input along with 10 extra inputs that represents the digit class. Finally, the output of the third RBM is used as the input of the fourth. (The diagram below is from his coursera class).
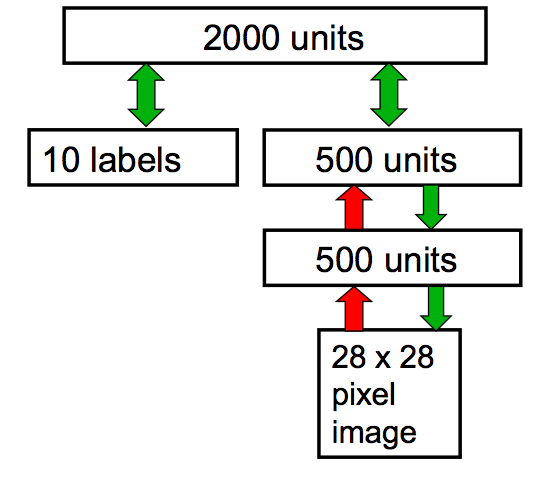
Training in its simplest form just builds on Contrastive divergence. You train the bottom RBM(‘A’ below) with the raw data first till it reaches equilibrium. Then start training ‘B’ by passing a training case through ‘A’ and using the output as a input for ‘B’. You do this over and over till ‘B’ is trained then do the same with ‘C’. The difference with C is you concatenate the Feature output of B along with the label input so the last RBM learns how to model these two.
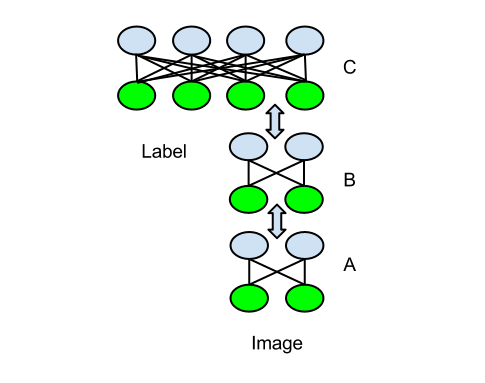
Once this DBN is trained you can take a test case and pass it through the layers to see what the output of the label nodes are activated, So passing a image ‘3’ will highlight the label ‘3’. So we have built the functional equivalent of the classic neural network I initially described but it’s a whole lot simpler, faster and more accurate.
Deep belief networks like this have subsequently be used to:
- Win the Netflix prize
- Power Google Voice
- Improve Predictive drug interactions
There are many variations on RBMs that have been developed and it’s fun to dig into how slight variations to this fundamental technique can be used to make it good at learning things other than just static inputs.
Generative Machines
By far the most interesting thing I’ve learned about Deep Belief Networks is their generative properties. Meaning you can look inside the ‘mind’ of a DBN and see what it’s imagining. Since a deep belief networks are two-way like restricted boltzmann machines you can make hidden inputs generate valid visual inputs. Continuing with our handwritten digit example you can start with the label input say a ‘3’ label and activate it then go reverse through the DBN and out the other end will pop out a picture of a ‘3’ based on the features of the inner layers. This is equivalent to our ability to visualize things using words, go ahead imagine a ‘3’, now rotate it.

Summary and Sample Project
Neural Networks have come a long way since I was in college. And what I like is they now fit the model of the mind I can recognize. The brain is truly an example of the whole is greater than the sum of it’s parts. And it seems like the stackable and generative properties of Restricted Boltzmann Machines have this as well.
If you want to really learn about this stuff please take the coursera course I mentioned. It’s taught by the foremost expert who created most everything I’ve covered.
I’ve implemented a simple RBM and DBN to create the handwriting example you’ve seen above. If you want to take a look and play with it the code is on my github. It’s java and you’ll see it’s really not that complex. A real implementation usually runs on the GPU to really speed up the training but it seems to run quickly enough and it’s got no external dependencies.
Next time I’ll dig a little deeper into the different RBM types out there and some of the more advanced training techniques (I’m still learning them).